What Is Machine Learning (ML)? Explained for Enterprises
What is machine learning (ML) in business terms? ML uses data to train models that improve decisions at scale, from forecasting to prioritization and personalization.

Machine learning (ML) is a method for building software models in artificial intelligence (AI) that learn patterns from data to produce outputs such as predictions, classifications, recommendations, or generated content, including text, images, audio, and video. Instead of coding every rule, teams define an objective, use representative data, and train models to optimize for the objective.
In contrast, traditional software relies on humans to specify logic for each scenario. ML replaces much of that rule-writing by learning decision patterns from examples, making it practical to tackle complex problems such as facial recognition and real-time fraud detection.
ML unlocks value from data at a scale and speed that traditional analytics and rule-based automation cannot match. It can improve decision accuracy, accelerate operations, and optimize performance in real time as conditions shift. Impact depends on data integrity, well-defined objectives, and ongoing system monitoring.
Organizations that delay adopting ML where it is structurally suited risk falling behind over time. As peers use predictive models to reduce manual effort and improve decision quality, late adopters can build a capability deficit that is difficult to close quickly, putting sustained pressure on efficiency and margins.
This article answers “What is machine learning?” in practical enterprise terms, explains how ML differs from related concepts, where it is used, and how to decide when and how to adopt it responsibly.
Key Takeaways
Machine Learning Definition
Machine learning is a branch of artificial intelligence (AI) in which algorithms learn patterns from training data to build models that predict outcomes, classify information, or generate outputs for new, unseen data. These models improve performance as they learn from more data and feedback, rather than relying on fixed, hand-coded rules.
Think of ML as learning by practice at scale, where the model identifies signals in historical data to guide future actions. It tackles problems that static, rule-based code struggles with, such as translating text, detecting cyber anomalies, forecasting demand, and generating content, including text, images, and audio.
Recent academic work frames ML as the capacity to learn from problem-specific training data and “automate the process of analytical model building.” This shifts the emphasis from theoretical “learning” to what matters operationally: the creation of repeatable models for forecasting, detection, ranking, and decision support.
Machine learning applications are not a one-time capital expense like a standard software license. Models can degrade as market conditions change (model drift), so leadership should treat ML as a living asset that requires ongoing monitoring, retraining, and governance.
Key Principles of Machine Learning
Machine learning holds up in the real world when four fundamentals are managed intentionally. These principles shape performance limits, operating cost, and governance needs long after a pilot.
The bottom line is an operational discipline. Durable results come from managing data, objectives, generalization, and lifecycle governance.
ML vs AI vs Deep Learning vs Generative AI
The cleanest way to visualize the landscape is a nested set plus an overlap. Machine Learning is a subset of Artificial Intelligence, and Deep Learning is a subset of Machine Learning. Generative AI (GenAI) refers to systems that generate or transform content and is most commonly implemented using deep learning and foundation models, but it is best treated as a capability category that overlaps with ML rather than a strict sub-layer.
Artificial Intelligence vs Machine Learning
Artificial Intelligence is the broad discipline focused on building systems that perform tasks typically associated with human intelligence, such as reasoning, planning, perception, and decision-making. Machine Learning is an AI approach that achieves these outcomes by learning patterns from data rather than relying solely on explicit rules.
AI can include ML, as well as non-ML approaches such as rule-based systems, optimization, planning, and knowledge-based methods. ML is typically chosen when the problem is pattern-heavy, measurable, and supported by representative examples, while non-ML AI approaches can be effective when rules and constraints can be specified clearly and maintained.
Choosing ML implies accepting ongoing responsibilities that many non-ML approaches do not require, including data stewardship, model monitoring, drift management, and periodic retraining.
Deep Learning vs Machine Learning
Deep Learning is a subset of Machine Learning that uses multi-layer neural networks to model complex, high-dimensional relationships. It is especially effective for unstructured data such as images, audio, text, and some sensor streams.
Compared to other ML approaches, deep learning often requires more data, more compute, longer training cycles, and a higher level of MLOps (Machine Learning Operations) maturity. It can also increase governance burden when explainability, auditability, or tight control over failure modes are required.
For many enterprise decisions involving tabular operational data, simpler ML approaches can deliver adequate performance at lower cost and with clearer accountability.
Generative AI vs Machine Learning
Generative Artificial Intelligence (GenAI) refers to systems that generate or transform content, such as text, images, code, audio, or summaries, based on learned patterns. In modern deployments, GenAI is most commonly built using deep learning architectures, particularly large foundation models fine-tuned or prompted.
GenAI systems are often implemented using ML, but they are optimized for different outcomes than many traditional ML deployments. Traditional ML commonly supports decisions such as classification, forecasting, ranking, or anomaly detection, while GenAI focuses on content generation and transformation.
That shift changes the risk profile. GenAI raises distinct concerns, including output reliability, hallucinations, content provenance, intellectual property exposure, and misuse, which typically require stronger human oversight and guardrails.
Data Science vs Machine Learning
Data Science is a broader practice that combines data exploration, statistical analysis, experimentation, and communication to extract insight from data. Machine Learning is one toolset within data science, focused on building models that can be deployed to operate repeatedly at scale.
Data science often informs understanding and prioritization, while ML operationalizes that understanding into production systems that influence decisions. Confusing the two commonly produces one of two outcomes: analytics work that never becomes operational, or ML work that launches without the context needed for robust measurement and governance.
The key takeaway is hierarchy and intent: AI is the umbrella; machine learning is a learning-based subset of AI; deep learning is a neural-network-heavy subset of ML; and generative AI is a class of ML systems that generate content, typically built with deep learning. Data science is the broader discipline that turns data into insight and operational systems, often overlapping with AI through ML.
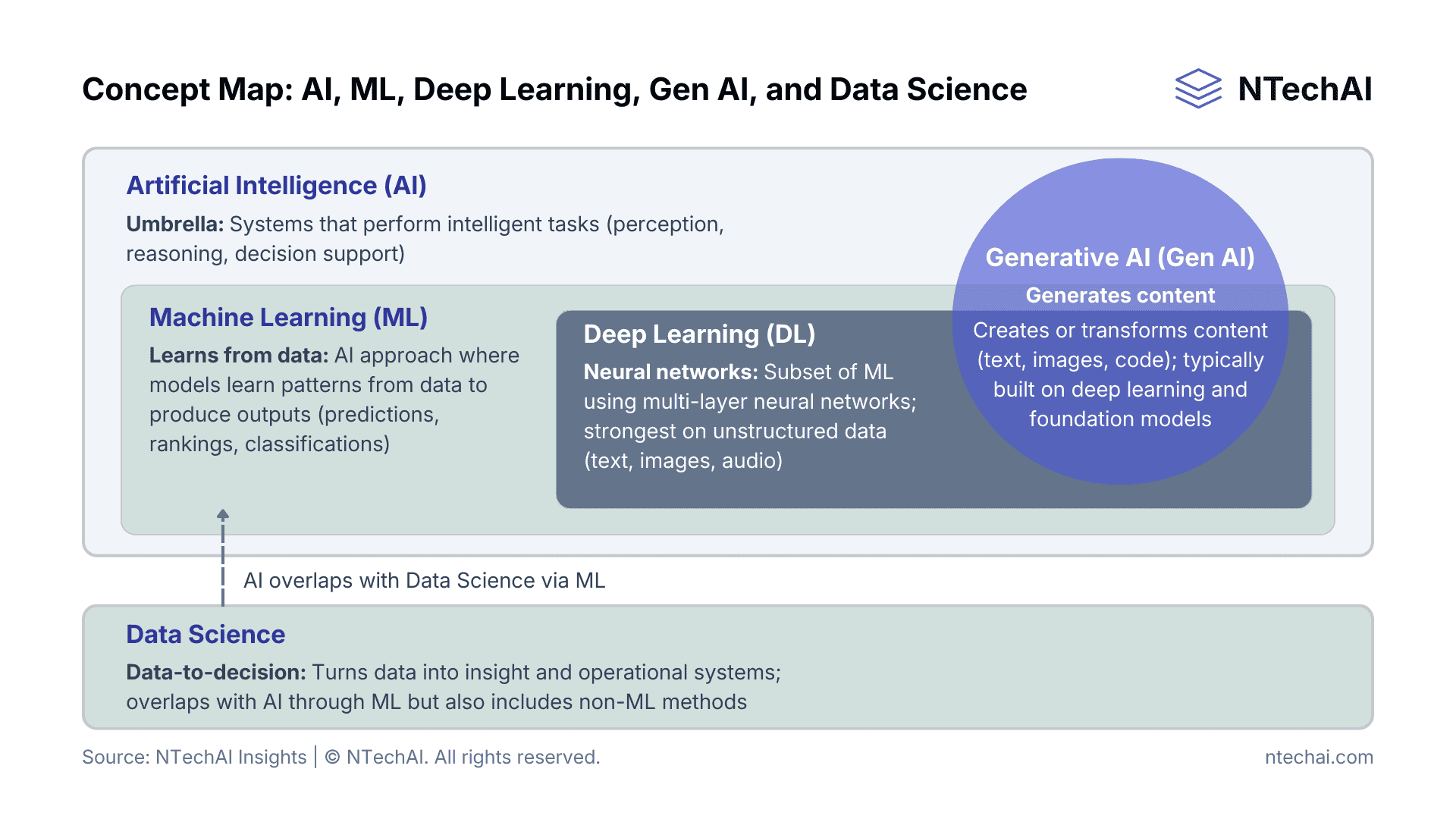
Concept map showing the nesting of AI disciplines. Note: Generative AI is typically understood as a content-generation capability built with deep learning, while data science is the broader discipline that turns data into insights and operational systems, often overlapping with AI through ML.
How Does Machine Learning Work?
Machine learning uses algorithms to analyze data and train mathematical models that can identify patterns and produce outputs such as predictions, classifications, rankings, or recommendations. Instead of following explicit programming rules, these models adjust internal parameters during training to minimize error with respect to a defined objective, then apply what they’ve learned to new inputs in production.
For decision-makers, understanding ML is less about the math and more about the intelligence supply chain. Knowing the core components and lifecycle stages helps leaders see where reliability is established, where constraints and trade-offs are set, where bias and compliance risk can enter, and where initiatives are most likely to break down.
Core Components of a Machine Learning System
To understand how machine learning works, focus on five components: data (examples), model (the model family and the trained model artifact), objective (the definition of success and error costs), algorithm (the training method), and compute (the resources required to train and serve).
This lens makes it easier to diagnose bottlenecks, set the right decision gates, and avoid systems that perform well in testing but fail in production.
1. Data: The set of examples a machine learning system learns from, including input features and, when available, labeled outcomes. It also includes the context needed to use those examples responsibly, such as provenance, permissions, and how ground truth will be captured after deployment.
2. Model: A mathematical function that maps inputs to outputs, such as predictions, classifications, rankings, or recommendations. In practice, a model family (e.g., linear models, decision trees, or neural networks) is chosen, and training produces a trained model (a specific fitted instance with learned parameters) that is the artifact deployed to generate outputs.
3. Objective: The definition of what “good performance” means for the model, typically expressed as a loss function plus constraints. It translates business goals and error costs into an optimization target, which is why misalignment here often results in systems that appear accurate but fail to deliver on those goals.
4. Algorithm: The method used to train a model by updating its parameters to improve performance on the objective. It shapes how training behaves in practice, including stability, reproducibility, noise sensitivity, and iteration speed.
5. Compute: The resources used to train and serve a machine learning system, including Central Processing Units (CPUs), Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), memory, storage, and networking. It determines feasibility, training time, inference cost, and production scale.
Treat these components as a supply chain rather than a checklist. Strong performance in one area rarely rescues weakness in another for long: unrepresentative data, a misaligned objective, or an unrealistic compute envelope will eventually show up as reliability, cost, or deployment problems.
When an initiative struggles, identifying the limiting factor is the first step toward remediation.
The Machine Learning Lifecycle
The machine learning lifecycle is the operating model for building, deploying, and keeping ML systems reliable in production. It is continuous because data, user behavior, threats, and business definitions change over time, which can degrade performance even when the code does not.
For decision-makers, the lifecycle functions as a governance framework. It translates a business objective into measurable outcomes via decision gates that keep costs, risks, and model drift within acceptable tolerances.
Phase 1: Problem Definition
Problem definition establishes the project’s strategic contract. It defines the decision the model will support and how it will be used in the workflow, whether in an advisory, assistive, or fully automated role. It also sets the non-negotiables: accountable owner, success metrics, error costs, and hard constraints for privacy, fairness, explainability, and latency.
Avoid the “accurate but unhelpful” paradox. A churn model can score attrition well and still fail to deliver ROI if it targets customers who are too far gone to save, or if it recommends actions that cost more than the value preserved.
Decision gate: Define the stop rule. If outcomes cannot be quantified, or if the cost of an error (for example, a false positive in fraud detection) exceeds the value of a correct hit, the initiative should not proceed with data collection.
Phase 2: Data Collection and Preparation
Reliable ML starts with a data foundation that matches production reality. Data collection and preparation combine acquisition with the transformations required to make inputs usable, representative, and aligned with real operating conditions.
Key activities include sourcing relevant datasets, validating legal permissions, ensuring label quality and consistency, and capturing edge cases that reflect how the system will be used in practice. Preparation then converts raw inputs into production-grade pipelines through cleaning, feature engineering, time alignment, and leakage prevention.
Many ML initiatives fail here because training data does not match production reality. Treat data pipelines as owned assets, not one-time extracts. Definitions, labels, and transformations should be standardized, versioned, and auditable so models learn from the same conditions they will encounter after deployment.
If a critical input cannot be computed reliably at decision time within latency or availability constraints, it must be redesigned or excluded, even if it improves offline accuracy.
Phase 3: Model and Algorithm Selection
Model and algorithm selection sets the operating trade-offs before training begins. The decision is less about choosing “the best model” and more about choosing a starting point that balances accuracy, explainability, latency, maintainability, cost, and risk tolerance.
Choose model families that fit the problem and governance needs, such as logistic regression for tabular data or neural networks for image and text tasks, and align them with a specific training algorithm (e.g., stochastic gradient descent or boosting) and controls like regularization or class weighting.
The goal is an approach that delivers results while remaining simple enough to operate safely.
For example, neural-network approaches can perform well on unstructured data, but they can be harder to interpret and more computationally expensive. Simpler models tend to be more transparent and easier to operate, but may plateau in accuracy.
Validate the runtime environment early. A large model cannot be deployed to an edge device with limited power and memory without compression, redesign, or degraded performance.
Phase 4: Model Training
This phase trains the model by learning parameters from prepared data to optimize the defined objective (loss function). It requires controlled experimentation, versioned data and code, tracked configurations and hyperparameters, and stored artifacts to reproduce and audit results.
Treat training as a versioned manufacturing process. If a pricing model behaves erratically, the team must be able to reproduce the exact training run to isolate the root cause, whether it is a corrupted data batch, a pipeline change, or a configuration shift.
Implement machine learning operations. Use model registries to track artifacts and enforce approval workflows before promoting a model from development to staging or production.
Phase 5: Evaluation and Tuning
This phase determines whether the model meets business and risk requirements on unseen data. It includes segment-level performance, robustness under drift, calibration, and threshold setting based on error costs and workflow capacity.
A model can score well overall while failing in a critical segment or missing rare, high-impact events. An equipment failure predictor that misses catastrophic breakdowns is operationally weak, regardless of average accuracy.
Review false positives and false negatives, check calibration, stress-test distribution shifts, and tune thresholds so outputs align with the organization’s ability to act, including review bandwidth, escalation policy, and latency tolerance.
Phase 6: Deployment and Integration
Deployment moves a validated model into production, where its outputs begin to shape real decisions. The work not only serves predictions but also integrates the system safely and reliably into workflows that act on the outputs.
Key considerations include inference architecture, latency budgets, failover behavior, access controls, and how model outputs trigger actions, recommendations, or automation. Integration must account for human-in-the-loop review, escalation paths, and fallbacks when confidence is low or when systems are unavailable.
Production deployment should always include clear rollback mechanisms. A model that cannot be disabled, throttled, or reverted quickly becomes an operational risk rather than a decision asset.
Best practice is to treat deployment as a controlled release, with staged rollouts, guardrails, and explicit ownership for production behavior from day one.
Phase 7: Monitoring and Maintenance
Once deployed, a machine learning system enters its most critical phase: sustaining performance, trust, and value over time. Unlike static software, ML systems degrade as data distributions, user behavior, and business conditions change.
Monitoring should cover three dimensions simultaneously: system health (latency, errors, availability), model behavior (input drift, output stability, confidence), and outcomes (business KPIs, error rates, overrides). Drift detection is essential, but it must be paired with clear thresholds and response plans.
Maintenance includes retraining, recalibration, threshold adjustments, and, when necessary, model retirement. Ownership must be explicit. Someone must be accountable for deciding when performance is no longer acceptable and what corrective action to take.
Best practice is to monitor lagging indicators, such as business outcomes, alongside leading indicators, such as shifts in data distribution, to detect problems before they materially affect decisions or customers.
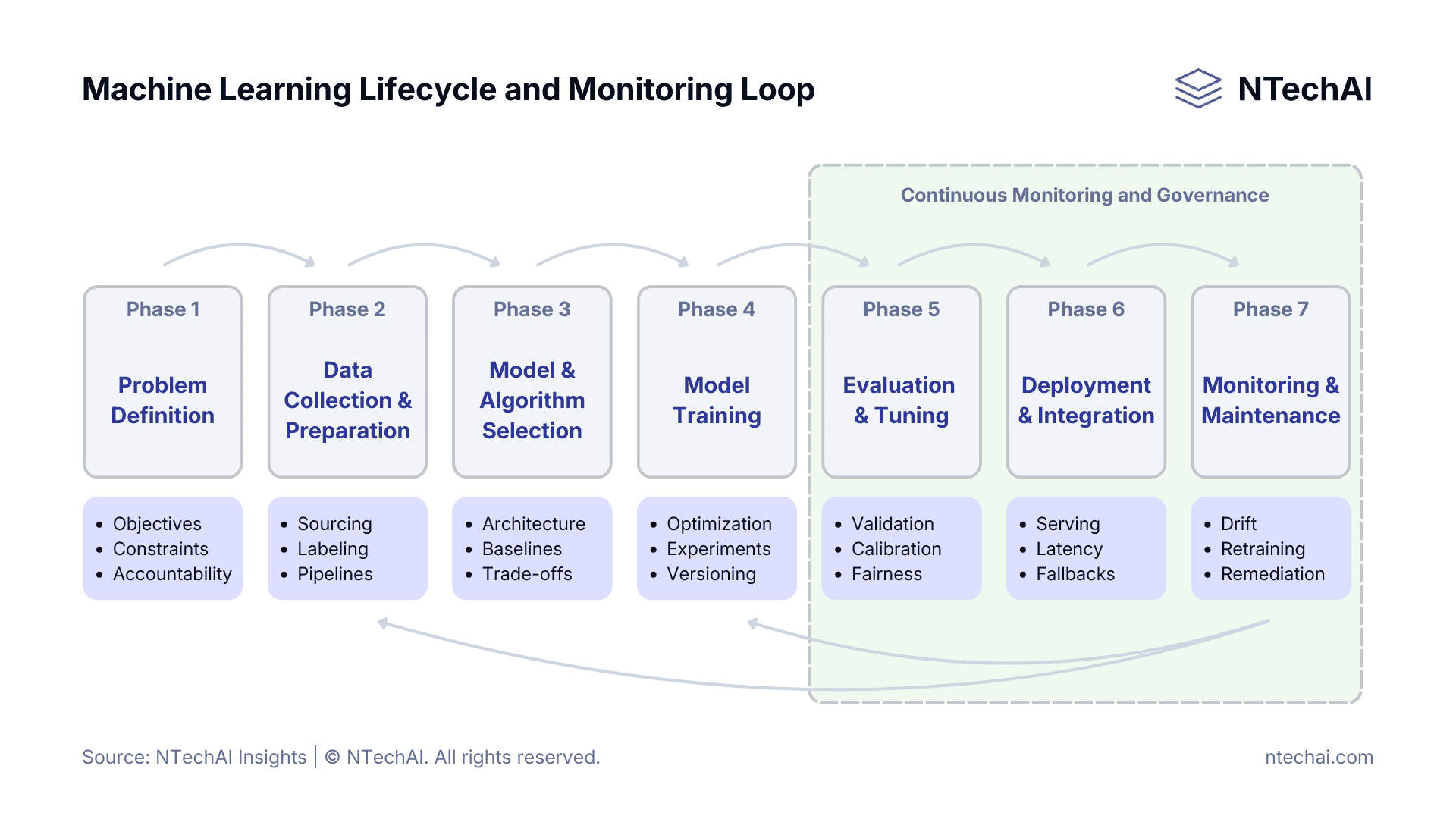
Machine learning is a continuous lifecycle. Monitoring and governance close the loop by tracking KPIs, detecting drift, and triggering retraining to maintain reliable production performance.
Types of Machine Learning
Machine learning algorithms are primarily categorized by how they learn, specifically by the type of data they consume and the feedback signal they receive during training. For enterprise leaders, understanding these distinctions is critical because the choice of approach dictates data requirements, cost structures, and the feasibility of specific business use cases.
1. Supervised Learning
Supervised learning is the most common form of machine learning in business applications today. It involves training a model on a labeled dataset, where every input example is paired with the correct output (the “ground truth”).
The model functions like a student with an answer key, making predictions on the training data and correcting itself whenever its answer does not match the known label.
2. Unsupervised Learning
Unsupervised learning involves training a model on unlabeled data. The system is given no “correct” answers or instructions on what to look for; instead, it explores the raw data to identify hidden structures, densities, or patterns on its own.
3. Reinforcement Learning
Reinforcement Learning (RL) is distinct from other types of learning because it learns from actions and their consequences rather than from static data. An RL agent operates within a dynamic environment and learns to make sequences of decisions by receiving feedback in the form of “rewards” or “penalties.”
4. Label-Efficient Learning
Label-efficient learning aims to deliver useful models when labeled data is scarce, expensive, or slow to obtain, improving performance with fewer labeled examples (as described in LabelBench).
This matters in domains where outcomes are rare (fraud), labeling requires experts (medical or legal), or the environment changes faster than labels can be produced. Some common patterns are:
A) Self-Supervised Learning
Self-supervised learning enables a model to generate its own supervision signals from the data.
A common technique involves hiding part of the input and asking the model to predict the missing piece (e.g., masking a word in a sentence and asking the model to fill in the blank).
This is the foundational technique behind modern foundation models and large language models, enabling them to learn language structure from billions of web pages without human labeling.
B) Semi-Supervised Learning
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data.
The model learns the general structure of the data from the unlabeled portion and refines its specific classification rules using the labeled portion. This approach significantly reduces data preparation costs while maintaining high accuracy.
C) Active Learning
Active learning optimizes the labeling process by having the model explicitly select the most “confusing” or informative data points for a human to review.
A common approach is to train an initial model, then prioritize labeling the cases where the model is most uncertain or where errors are most costly. Over repeated cycles, the model improves while requiring far fewer labeled examples than traditional supervised training.
In enterprise settings, label-efficient approaches often reduce reliance on manual labeling pipelines but increase the importance of evaluation discipline, since improvements can be harder to attribute and failure modes can be subtle.
What Is Machine Learning Used For?
In the modern enterprise, machine learning applications help convert data into business value by turning information into predictions, classifications, rankings, and generated outputs that can be embedded into workflows. It is especially useful for extracting signal from unstructured data such as text, images, audio, and sensor logs, where traditional analytics often struggles.
When applied properly, ML shifts organizations from retrospective reporting toward more proactive decision support and selective automation. Common enterprise use cases include:
1. Perception: Vision, Speech, Text, and Sensor Intelligence
Machine learning enables systems to interpret unstructured data that was previously readable only by humans. Through Computer Vision (CV) and Natural Language Processing (NLP), algorithms convert pixels, audio waves, and text strings into structured data.
In practice, this powers capabilities like automated quality inspection on manufacturing lines, sentiment analysis of customer support logs, and voice interfaces for hands-free operations. It converts pixels, audio, and free text into structured signals that downstream systems can validate, route, and act on.
2. Recognition: Pattern Recognition and Classification
At its core, ML excels at categorizing inputs into defined groups based on learned characteristics. This function, often called classification, automates high-volume sorting tasks.
Enterprise examples include email filtering (sorting spam from priority), document indexing (identifying invoices vs. contracts), and diagnostic imaging (classifying X-rays as normal or showing signs of pathology).
3. Detection: Anomaly Detection, Fraud, and Cybersecurity
By establishing a baseline of “normal” behavior using historical data, ML models can identify deviations in real time with far greater nuance than static rules. This is critical for high-stakes environments where speed is essential.
Financial institutions use this for fraud detection, flagging transactions that deviate from a user’s typical spending pattern, while IT security teams deploy it to detect network intrusions that bypass traditional firewalls.
4. Prediction: Forecasting, Risk Scoring, and Demand Planning
Predictive analytics uses historical trends to calculate the probability of future outcomes. Unlike traditional forecasting, which often relies on linear extrapolation, ML models can ingest hundreds of variables, including seasonality, market indicators, and external data, to model complex scenarios.
Common applications include predicting customer churn, scoring credit risk for loan applicants, and forecasting supply chain demand to optimize inventory levels.
5. Recommendation: Personalization and Next-Best Action
Recommendation systems act as filtering engines that match users with the most relevant items or actions.
While well-known in consumer retail (product recommendations) and media (content playlists), this capability delivers significant value in B2B contexts as “Next-Best Action” models.
These systems analyze a client’s history and behavior to guide sales representatives toward the specific offer or service intervention most likely to succeed.
6. Optimization: Decision Optimization and Operational Efficiency
Optimization focuses on choosing what to do while meeting constraints. ML often contributes by estimating inputs to optimization (for example, demand, duration, or risk), which then informs scheduling, routing, inventory planning, or capacity allocation.
The value is highest when ML outputs are paired with explicit constraints and decision rules, ensuring recommendations remain feasible and accountable.
7. Creation: Generative AI for Content and Productivity
The emergence of Generative AI expands ML’s utility from analysis to synthesis. Instead of just classifying data, these models generate new content (text, code, images, or synthetic data) based on learned patterns.
Enterprises use this to accelerate software development via code assistants, draft marketing copy at scale, or generate synthetic datasets to train other models without compromising user privacy.
8. Automation: Document Processing and Workflow Routing
When combined with Robotic Process Automation (RPA), machine learning creates Intelligent Automation.
While RPA handles repetitive clicks and keystrokes, ML handles the cognitive judgments, such as reading a non-standard invoice, extracting the total due, and deciding which department must approve it.
This enables end-to-end processing patterns for invoices, claims, onboarding, and case triage, while keeping oversight where judgment is required.
Benefits of Machine Learning in Business
Machine learning delivers value when it improves the speed, quality, or consistency of decisions at scale. The benefits are most evident in repeatable processes where outcomes can be measured, models can be monitored, and teams can keep performance aligned with changing conditions.
High-Speed Decision Intelligence
Machine learning can convert high-volume data streams into near-real-time scores, alerts, and recommendations, thereby shortening decision cycles in areas such as operations, security, and customer interactions. Instead of waiting for periodic reporting, teams can act on leading indicators as conditions shift.
In practice, the advantage is less about “instant answers” and more about consistent decision support at the point of work, where latency and scale make manual review impractical.
Operational Efficiency and Intelligent Automation
ML can reduce manual effort by automating classification, routing, forecasting, and exception handling. This often improves throughput and lowers costs by focusing people on cases that truly require judgment rather than the full volume of routine work.
Efficiency gains are typically strongest when ML is embedded in a redesigned workflow, where the organization also standardizes inputs, defines escalation paths, and measures end-to-end outcomes.
Personalization That Lifts Revenue and Experience
Machine learning supports personalization by ranking content, products, or actions based on observed patterns. Common outcomes include more relevant recommendations, improved self-service experiences, and better targeting of offers or interventions.
The practical constraint is the quality of data and feedback: personalization improves when signals are representative, consented to where applicable, and tied to outcomes the business actually cares about.
Risk Reduction (Fraud, Cybersecurity, Compliance)
ML can reduce risk by detecting anomalies and scoring suspicious behavior in domains such as fraud detection and security threat identification.
This is most valuable when the organization can calibrate thresholds, measure false positives, and continuously tune models as adversaries and behaviors change.
For regulated use cases, risk reduction also depends on governance: clear documentation, appropriate validation, and ongoing monitoring to manage reliability and unintended impacts.
Scalability and Continuous Improvement
Once deployed, ML can scale decisions across channels and geographies with consistent logic, while continuing to improve as new data is collected and performance is monitored. This is a key difference from static rulesets, which often become brittle and expensive to maintain as complexity grows.
The boundary is operational maturity: the benefits of continuous improvement require lifecycle practices such as monitoring, retraining triggers, and accountability for model behavior in production.
Risks and Challenges of Machine Learning
Machine learning systems can create material value, but they also introduce risks that do not appear in traditional software. Because model behavior is learned from data and context, failures often show up as unexpected performance, uneven impact, or operational drift rather than deterministic bugs.
Frameworks such as the NIST Artificial Intelligence Risk Management Framework, the OECD AI Principles, and ISO/IEC 23894 highlight these risk areas and emphasize lifecycle-based controls.
Bias, Fairness, and Explainability
Machine learning models are mathematical mirrors of the data used to train them. If historical data contains societal prejudices or systemic inequalities, the model will learn, replicate, and amplify those biases.
This phenomenon, known as algorithmic bias, can lead to discriminatory outcomes in hiring, lending, or healthcare, creating severe legal and reputational liability. Compounding this issue is the “black box” nature of complex models (particularly deep learning), where the internal decision-making logic is opaque.
Without Explainable AI (XAI) tools to interpret why a decision was made, organizations struggle to audit models for fairness or justify decisions to regulators and customers.
A common enterprise failure mode is treating fairness and explainability as “post-model” tasks. In practice, they often require upstream design choices: which data are collected, what is labeled, how success is defined, and which monitoring signals are maintained after launch.
Reliability, Drift, and Model Risk
Models can degrade when the real world changes, even if the code does not. Input distributions shift, user behavior evolves, suppliers and processes change, and new products or policies create conditions that were not present in training data.
Operationally, this manifests as data drift (inputs change), concept drift (the relationship between inputs and outputs changes), or silent failure, where the model still produces confident outputs but is wrong more often. Monitoring guidance emphasizes continuously tracking production behavior and performance signals, because ML systems do not remain stable by default.
This also creates model risk: when an ML system influences high-impact decisions, teams need clear thresholds, rollback paths, and ownership for responding to degradation. Without that, ML becomes a reliability liability rather than a decision asset.
Privacy, Security, and Governance
ML expands the organization’s attack surface and governance burden by relying on large data flows and producing outputs that can be misused or manipulated.
Privacy risk increases when sensitive data is collected or repurposed beyond its original context, and governance risk increases when teams cannot document data lineage, model intent, and decision accountability.
Security threats can be specific to machine learning. A NIST publication on adversarial ML describes attacks such as poisoning and evasion that can degrade or manipulate model behavior across the lifecycle.
A practical implication is that governance must cover the full lifecycle: data controls, model validation, deployment approvals, monitoring, and incident response. Treating ML governance as a one-time review step is rarely sufficient in production environments.
Cost, Complexity, and Organizational Readiness
The total cost of ownership (TCO) for ML initiatives is frequently underestimated. Beyond the obvious costs of cloud compute and data storage, there are hidden costs in data cleaning, labeling, and ongoing maintenance (MLOps).
Additionally, there is often a “cultural gap” in readiness; business units may struggle to trust probabilistic systems that cannot guarantee 100% accuracy, which can lead to low adoption rates.
Successful implementation requires not just data scientists but also a broader workforce that is upskilled to interpret and act on ML-generated insights effectively.
Best Practices for ML Systems
Enterprise machine learning succeeds when it is treated as a decision capability with lifecycle ownership, not a one-time model build. This section focuses on practices that reduce avoidable failure modes: unclear decision scope, weak data foundations, unmanaged drift, and governance gaps that surface only after deployment.
1. Start With the Decision
Start by specifying the business decision the system will support, including who will use the output, when it will be used, and what action it will take. This prevents teams from optimizing for generic model accuracy when the real goal is decision quality, speed, or risk reduction.
Define boundaries early: which cases are in scope, what is explicitly out of scope, and what fallback to use when the model is uncertain. This turns “use ML” into an implementable operating design rather than an abstract analytics effort.
2. Define Success and Stop Rules
Define success in measurable terms that reflect the decision, not just the model (for example, cost avoided, false-positive tolerance, cycle time reduction, service-level impact). Pair those metrics with acceptance criteria that must be met before production use.
Equally important, define stop rules: conditions that trigger pauses, rollbacks, or redesigns (for example, drift beyond a threshold, unacceptable subgroup performance gaps, missing monitoring signals, or an inability to obtain valid labels).
This aligns effort with governance expectations and limits uncontrolled model risk.
3. Build Strong Data Foundations
Treat data as a product dependency: document data sources, lineage, quality checks, and how labels are generated. When training data does not match real operating conditions, models often perform well in development but fail quietly in production.
Prioritize representativeness and stability over volume alone. If the business expects the model to work across regions, seasons, channels, or segments, the data strategy must cover those operating ranges and capture changes over time.
4. Operationalize with MLOps
Machine Learning Operations (MLOps) applies software delivery discipline to ML, including repeatable pipelines for data, training, evaluation, and deployment. Best practices for ML delivery automation highlight how to reduce handoffs and improve production reliability.
In practice, this means versioning data and models, automating tests for training and inference, and enforcing repeatable promotion gates (development, staging, and production). It also means designing retraining as an operational capability rather than a one-off event.
5. Design for Monitoring and Oversight
Assume the model will degrade unless it is monitored. Monitoring should cover inputs (data drift), outputs (prediction distribution shifts), and outcomes (business performance signals) with clear thresholds and incident response paths.
Microsoft’s guidance on drift emphasizes regular monitoring, root-cause analysis when drift is detected, and automation that connects monitoring to retraining and redeployment workflows.
Governance frameworks reinforce that oversight should span design through ongoing use, not just pre-deployment review. Cross-functional ownership (product, engineering, risk, legal/compliance, where relevant) is typically required for high-impact decisions.
6. Run ML as a Lifecycle
Operate ML as a continuous loop: define and validate, deploy with controls, monitor and measure, then improve or retire based on evidence. This aligns with NIST’s lifecycle-oriented view of governing, mapping, measuring, and managing AI risks as conditions change.
A practical boundary is that if an organization cannot commit to lifecycle operations (monitoring, retraining triggers, accountability, documentation), ML should be scoped down to lower-risk use cases or deferred until readiness improves.
ML Decision Framework
To navigate the hype cycle, enterprise leaders require a consistent rubric for evaluating potential use cases of machine learning systems. This framework synthesizes the technical, operational, and ethical dimensions of machine learning into four strategic gates.
Projects should proceed to the proof-of-concept phase only when they can answer the core question in each category affirmatively, ensuring resources are focused on viable, high-impact initiatives.
1. Value Proposition
Does this problem actually require probabilistic reasoning?
If a traditional rule-based system (simple if-then logic) can achieve 80% accuracy at 10% of the cost, machine learning systems are likely over-engineering. ML generates the highest ROI in high-scale, high-variance tasks where manual logic is too brittle to succeed.
Furthermore, the projected value must exceed the total cost of ownership, which includes not only the initial build but also the ongoing costs of retraining, data storage, and model monitoring.
2. Risk Profile
What is the cost of a wrong prediction?
In a movie recommendation engine, a bad prediction is a minor annoyance; in a medical diagnosis system or autonomous vehicle, it can be catastrophic. Leaders must define the “error budget” (the acceptable margin of failure) before development begins.
High-risk applications require stricter guardrails, “human-in-the-loop” review processes, and higher explainability standards than low-risk internal optimizations.
3. Operational Readiness
Is the data infrastructure mature enough to support production? The most common bottleneck in ML adoption is not algorithmic complexity, but data accessibility. A “Go” decision requires a pipeline that guarantees data availability, quality, and lineage.
If the necessary data is siloed, legally restricted, or requires manual cleaning for every run, the organization is not yet ready for automated learning, and investment should shift to data engineering first.
4. Accountability and Governance
Who owns the model when it breaks? Unlike static software, ML models drift and degrade over time. A clear line of accountability must be established to monitor performance, audit for bias, and ultimately retire the model when it no longer serves its purpose.
Without a designated owner responsible for the model’s lifecycle, an ML asset quickly becomes a liability of unmanaged technical debt.
A decision-quality “go/no-go” outcome is usually clear when these dimensions are applied together: strong value with manageable risk, proven readiness, and explicit accountability tends to produce durable ML systems. Gaps in readiness or ownership tend to convert ML into ongoing operational debt.
Sources
Institutional & Standards References
[1] National Institute of Standards and Technology (NIST) (2023). “Artificial Intelligence Risk Management Framework (AI RMF 1.0)”. [Linked Above] Supports: Lifecycle risk taxonomy and governance/controls for AI systems.
[2] National Institute of Standards and Technology (NIST) (2025). “Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations”. [Linked Above] Supports: Taxonomy of adversarial ML threats (poisoning, evasion) across the ML lifecycle.
[3] Organisation for Economic Co-operation and Development (OECD) (2024). “OECD AI Principles”. [Linked Above] Supports: High-level trustworthy AI principles used for policy and enterprise governance alignment.
[4] International Organization for Standardization (ISO/IEC) (2023). “ISO/IEC 23894:2023, Information technology — Artificial intelligence — Guidance on risk management”. [Linked Above] Supports: Risk management guidance specifically for AI across development and use.
Academic & Research References
[5] Mitchell, T. M. (Carnegie Mellon University, 1997). “Machine Learning”. [View Source] Supports: Canonical academic definition and foundations of ML as learning from experience/data.
[6] Janiesch, C. et al. (Springer Nature, 2021). “Machine learning and deep learning”. [Linked Above] Supports: Clear ML definition and ML vs deep learning distinction.
[7] Zhang, J. et al. (arXiv, 2022). “LabelBench: A Comprehensive Framework for Benchmarking Adaptive Label-Efficient Learning”. [Linked Above] Supports: Defining label-efficient learning and a benchmarking framework.
Enterprise & Analyst References
[8] Google (Google Cloud, 2024). “MLOps: Continuous delivery and automation pipelines in machine learning”. [Linked Above] Supports: MLOps pipelines from experimentation to production.
[9] Amazon (Amazon Web Services, 2023). “Machine Learning Lens – AWS Well-Architected Framework”. [View Source] Supports: Practical controls and design principles for production ML systems.
[10] TechTarget (2024). “What is machine learning? Guide, definition, and examples.” [View Source] Supports: Enterprise explainer coverage (types, implementation considerations, use cases).
Notes
Editorial Notes
This article provides a decision-support analysis. It is written to improve clarity, accuracy, and real-world application for enterprise leaders, operators, and technical practitioners.
Where concepts or terminology vary across academic, industry, or regulatory sources, we prioritize definitions and framing that are broadly accepted and operationally meaningful.
AI & Editorial Disclosure
AI tools were used to support research, outlining, structural organization, and drafting.
All content was reviewed, fact-checked, and edited by human reviewers to ensure accuracy, context, and alignment with current engineering and governance standards. No part of this article was published without human oversight.
Corrections & Accountability
If you find a factual error, a source issue, or outdated information, please contact us at info@ntechai.com.
To learn more about our mission and editorial standards, visit our About page, or explore NTechAI Insights for ongoing analysis.
Rights & Attribution
© NTechAI. All rights reserved. Portions of this content may reference open research and academic concepts credited to their respective authors. All original content is protected by copyright law and may not be reproduced without permission, except as permitted by law.





